# 5. 模板分析
# 5.1 概述
数据分析中除了常用的事件分析、属性分析、分群分析外,其它分析模型(如漏斗、留存、关联、路径、分布以及其它分析模型)均可通过模板分析实现。
使用模板分析搭建图表,首先需要“选择模板”,系统则会根据选择的模板自动加载相应的“模板规则”,然后根据业务需要定义模板规则,最终保存为卡片。如下图:
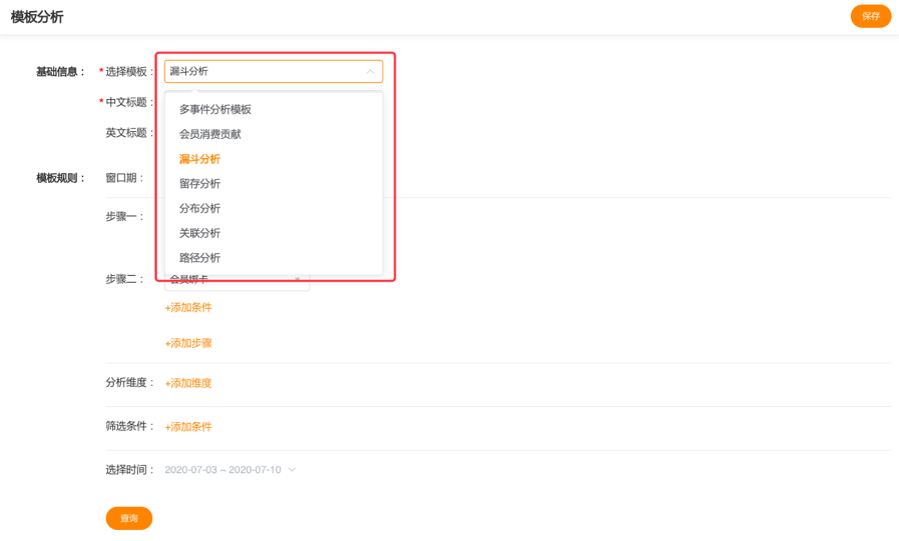
以下分别介绍主要几个模板的功能。
# 5.2 漏斗分析
漏斗模型主要用于分析一个事件整体的转化以及多步骤过程中每一步的转化与流失情况。如下图:
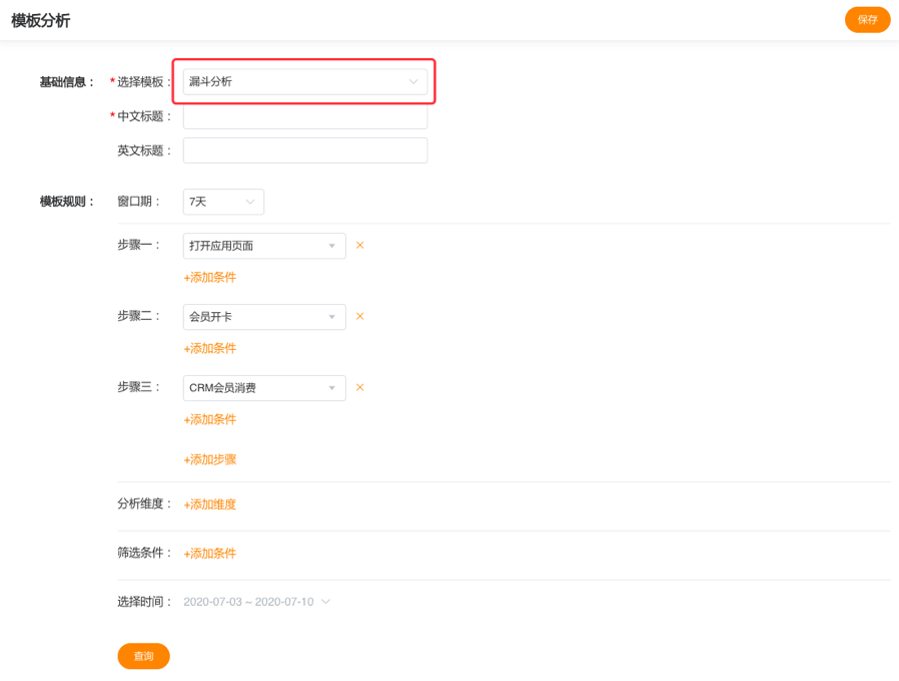
漏斗分析模型的规则中包括以下几个概念:
# 5.2.1 窗口期
用户完成漏斗的时间限制,也即只有在这个时间范围内,用户从第一个步骤,行进到最后一个步骤,才能被视为一次成功的转化.
# 5.2.2 步骤
由一个 元事件/虚拟事件 加一个或者多个筛选条件组成,表示一个转化流程中的一个关键性的步骤,一个漏斗中至少包含 2 个步骤,每个步骤对应一个事件(可附带一个或多个筛选条件);
# 5.2.3 时间范围
在界面上选择的时间范围,是指漏斗的第一个步骤发生的时间范围;
除了上述“步骤、窗口期、时间范围“关键信息外,漏斗分析还可以通过”分析维度“和”筛选条件“进行深度分析。
# 5.2.4 分析维度
任意步骤的公共属性:按照每个用户该属性的首次有效值进行分组,一个用户只会出现在一个维度(分组)中;
各步骤的事件/实体属性:按照每个用户首次最长转化状态中的第 XX 步骤的事件/实体属性值进行分组 ,一个用户只会出现在一个分组中,如果用户没有转化到该步骤则分到未知组;
用户属性:按照用户属性筛选。
# 5.2.5 筛选条件
任意步骤的公共属性:以每个用户YY属性的首次有效值进行筛选;
XX 步骤的 YY 属性:以每个用户首次最长转化状态中的第 XX 步骤的 YY 属性值进行筛选;
用户属性:按照用户属性值筛选;
说明
如果这里选择的属性是数字类型,可以自定义分组区间。如果没有设置,查询引擎会动态计算分组区间。此设置仅在当前查询生效,将查询保存为卡片后在卡片中也生效。
# 5.3 留存分析
留存分析是一种用来分析用户参与情况/活跃程度的分析模型,考查进行初始行为后的用户中,有多少人会进行后续行为。如100人注册会员开卡后,有多少人7日内有过消费行为。如下图:
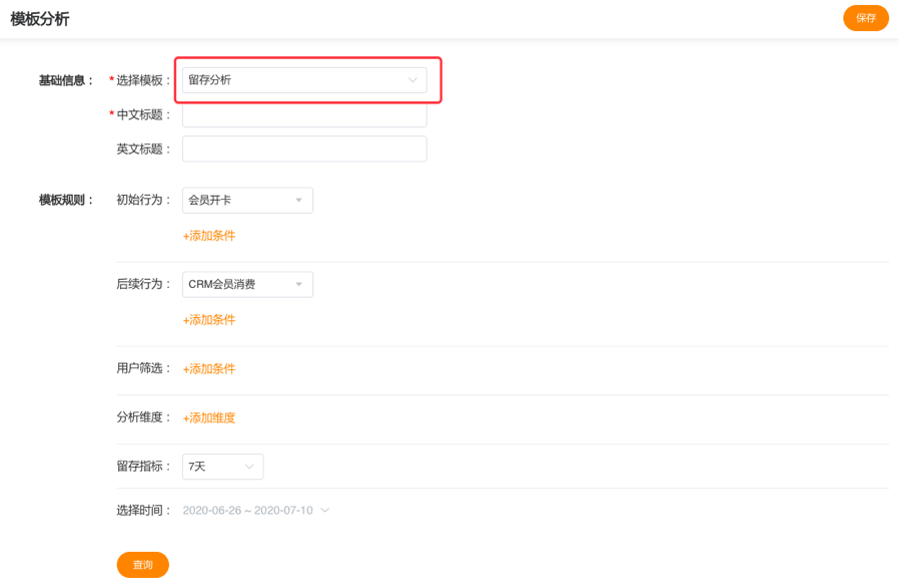
# 5.3.1 初始行为和后续行为
初始行为和后续行为的选择需要遵循自身的业务逻辑,一般存在两种选择方式:
# 第一种情况:
初始行为选择某一事件(如购买团购),后续行为选择初始行为后可能发生的事件(如核销团购),这种留存用于分析不同阶段开始使用产品用户的参与情况,从而评估产品迭代或运营策略调整的得失;
# 第二种情况:
初始行为和后续行为选择相同,如“crm会员消费”,期待用户重复触发的事件,这种留存用于分析忠实用户的使用模式。
# 5.3.2 初始行为和后续行为的筛选条件
针对事件的属性,可以根据具体需求筛选初始行为或后续行为的细分维度。
举个栗子
比如,分析通过微信渠道开卡的会员,后续crm会员消费的留存情况,那么可以定义初始行为是“会员开卡”,同时添加筛选条件“事件来源等于微信”,后续行为是“crm会员消费“,即可满足分析需求。
# 5.3.3 分析维度
留存分析支持按事件或实体属性进行分组:
# 按实体属性分组:
根据用户属性进行进一步分组。如分析维度是“性别”,那么,就会分别对留存分析的结果按照“男”、“女”来进行分组。
# 事件属性的分组:
如分析维度的初始行为(会员开卡)的事件属性是“卡级名称”,则这个分组表示,按初始行为的“卡级名称”这个属性的值来对他们进行分组;如分析维度的后续行为(crm会员消费)的事件属性是“实付金额”,则这个分组表示,按后续行为的“实付金额(按区间设置)”属性值进行分组。
# 5.3.4 筛选条件
针对用户属性,筛选更为精准的分析对象。如,只查看女性用户的留存情况。
通过添加用户的属性筛选条件,可以缩小满足条件的用户范围。当添加了多个筛选条件时,它们之间的关系可以通过点击“且”字占位符在且关系和或关系之间切换,选择“且”代表指标要符合每个筛选条件,选择“或”代表指标只需要符合一条或多条筛选条件。
# 5.3.5 留存窗口
留存窗口设定的初始行为事件发生后,后续事件发生时间范围的截止日期会被延展的时间长度。
举个栗子
留存的初始行为是 A 事件,后续行为是 B 事件,留存窗口设置为7天,筛选时间段为 2020 -07-01至 2020-07-08,则该时间范围指的是事件 A 发生的时间范围,事件 B 发生的时间范围是 2020-07-01至 2020-07-15 (7月 8 日加上 7 天)。
关于留存计算方式
留存分析中展示的数字代表独立用户数。表示在选定时间范围内进行了初始行为的用户,有多少人在随后的第 n 天/周/月进行了后续行为。
# 5.4 分布分析
分布分析可以反映用户或店铺对商场服务的依赖程度,也可以反映某个事件指标的用户或店铺的分布情况,如查看“crm会员消费”的“实付金额”在 100 元以下、100 元至 200 元、200 元以上三个区间的用户分布情况。如下图:
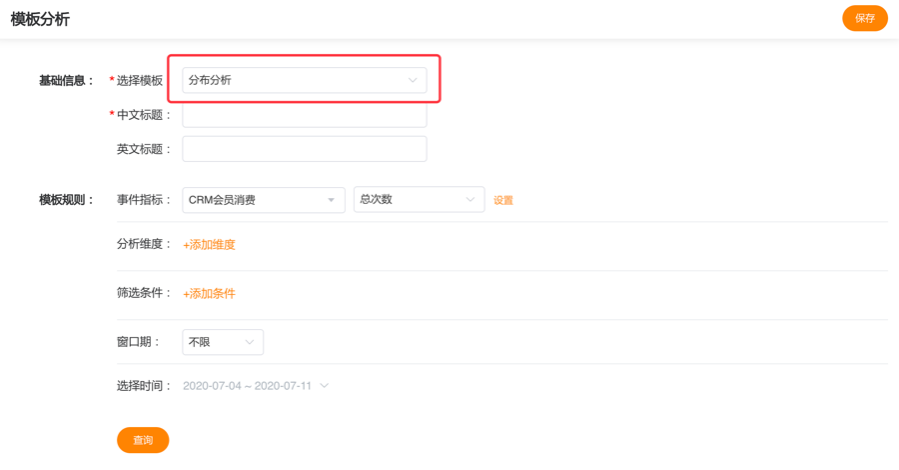
# 5.4.1 事件指标
指定一个事件,然后再选择事件的指标。如“crm会员消费”的“总人数”。

1)若事件指标选择“数字”类型属性时,所用的控件中选择分为三种,默认选择第一种.
数字区间说明
固定区间1: 按照指标自然区间划分,如“1 次,2 次,3 次......”
固定区间2: 按照指标自然区间加和递减划分,如“至少 1 次,至少 2 次,至少 3 次......"
自定义区间: 由用户来定义区间划分数值。
2)若事件指标选择“字符串/时间”类型时,如“crm会员消费的会员卡号去重值”, 所用的控件包括“默认区间”和“使用自定义区间”,其中“默认区间”划分规则通用,和具体业务无关,
字符串/时间区间说明
猫酷定义为“0~10、10~30、30~50、50~100、100~200、200~500、500~1000、1000~5000、 5000~10000、10000~50000、50000~100000、100000 以上”这些组。
# 5.4.2 分析维度
分布分析支持通过多个维度分析数据,如,查看每个会员卡级的用户CRM会员消费分布情况。
# 5.4.3 筛选条件
通过添加筛选条件,可以精细化查看符合某些具体条件的用户分布情况。如,只查看女性用户节假日的CRM会员消费的分布情况。
# 5.4.4 窗口期
选择行为发生的统计时间窗口。
窗口期说明
不限: 即用户在所选时间范围内的行为分布;
一天内: 用户在 0:00-23:59 这 24 小时中的行为分布;
一周内: 用户在周一到周日这 7 天内的行为分布;
一个月内: 用户在不同月份的第一天到最后一天的行为分布.
# 5.5 关联分析
关联分析是用来发现用户在某事件中行为数据的相关性,从而描述了一个事件中某些属性同时出现的规律和模式,如查看用户在A店铺消费后还在哪些店铺有过消费。如下图:
# 5.5.1 关联规则
即同一事件某一属性之间的关联规则,如到达店铺 Nike 的人会去 Adidas,则 Nike 和 Adidas 之间便存在关联。
关联分析模型最终得出的指标是固定的,以到达店铺的店铺名称等于星巴克为例,这四个指标分别为:
关联人数: 一段时间内,既去了星巴克又去了某家店铺的人数。
关联度: 一段时间内,既去了星巴克又去了某家店铺的人数占去星巴克总人数的比例。
反向关联度: 一段时间内,既去了星巴克又去了某家店铺的人数占去某家店铺的的比例。
提升度: 提升度计算规则比较复杂,这里只说明数值的实际应用价值。
应用价值
a)当 0<提升度<1,去星巴克的人数越多(少),则去某家店铺的人数越少(多),两者互斥;
b)当提升度=1,去星巴克的人数与去某家店铺的人数之间不相关;
c)当 1<提升度<=3,去星巴克的人数越多(少),则去某家店铺的人数越多(少),但两者关联程度不明显;
d)当 3<提升度,去星巴克的人数越多(少),则去某家店铺的人数越多(少),两者关联程度明显。
# 5.5.2 筛选条件
通过筛选条件,可以缩小满足指标的数据范围。筛选条件分为两种:
a)事件属性的筛选条件,如到过“餐饮业态“店铺的用户,还去过其他店铺;
b)关联事件属性的筛选条件,如到过“餐饮业态“店铺的用户,还去过”服装业态“的店铺。
# 5.6 路径分析
路径分析用于分析用户线上/线下行为的路径分布情况。例如,顾客访问了微信/轻应用首页的用户后,有多少顾客进入了团购列表,有多少顾客进入了积分兑换列表,有多少用户直接访问了店铺列表。如下图:

# 5.6.1 选择事件
路径分析仅适用于用户的行为事件的路径分析,每个事件均可设置分组,且每个事件最多一个分组。
# 5.6.2 路径设置
可以设置选择的事件组中某个事件为分析的起始事件或者结束事件,或选择某一事件为双向事件,如下图:

# 5.6.3 窗口期
设置需要分析的时间区间,意味着要分析的事件都发生在该时间区间内,选定后再对用户和事件进行分析。
# 5.6.4 查看路径
分析结果以桑基图形式展现,以目标事件为起点/终点,详细查看后续/前置路径,可以详细查看某个节点事件的流向。如下图:

说明
对于每个事件节点,可以点击该节点,选择查看节点详细信息,即可查看当前节点事件的相关信息,包括事件名,分组属性值(如果有分组的话),合计,后续事件统计,流失 ,后续事件列表。其中后续事件列表中会详细列出当前事件的会话数和分组值(如果有分组的话)。更进一步,可以点击每一行末尾的图标查看对应的用户列表,进而查看每个用户的行为序列。